The Top Level Ecommerce SEO & AI SEO Platform for Professionals
Always be a step ahead in Ecommerce SEO and AI SEO with our WDF*IDF tool, workshops, and valuable SEO resources, plus get 1-on-1 SEO consultations when you need it most. Use our certification program, professional SEO profiles, and Freelancing Masterclass to stand out and acquire well-paying clients.
"I have known Nedim for several years and would not want to miss the exchange with him. He is not only a luminary in the field of eCommerce SEO, but also knows how to convey this valuable knowledge properly."
Head of SEO @ Conrad.de
★★★★★"The content on SEOLAXY can't be found anywhere else. You can't find people sharing that level of knowledge anywhere else. The provided shortcuts allowed my to kickstart my SEO freelancing career. Today I am an SEO agency owner."
Owner @ Hourix
★★★★★"SEOLAXY changed my life! I landed my first client in the USA very quickly. Since then, I've worked across multiple niches in the U.S. market and delivered outstanding results. I was even invited to be a guest speaker at New York University. Thank you for everything!"
SEO Specialist @ Digital Silk
★★★★★What's Inside SEOLAXY?
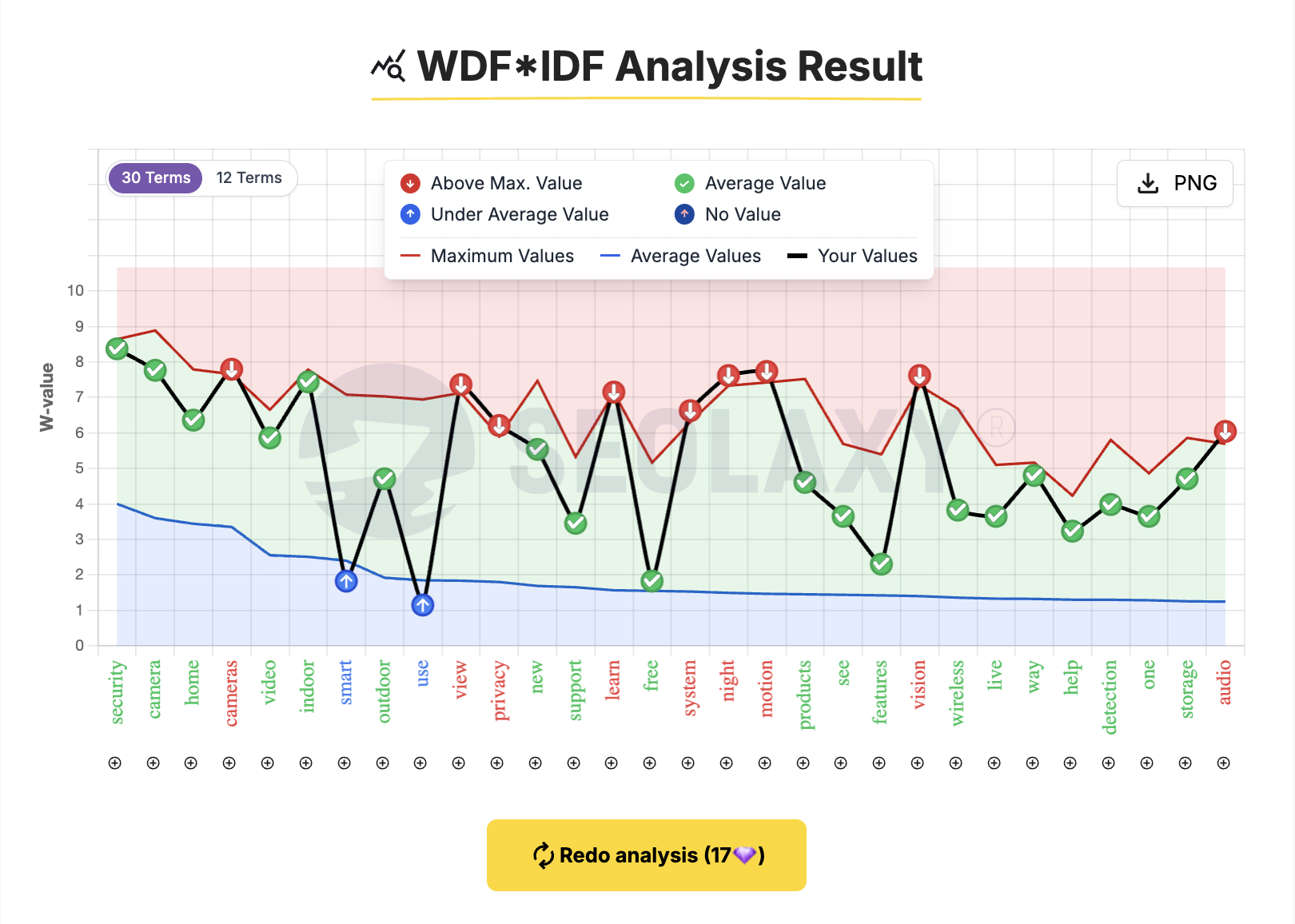
WDF*IDF Tool
Write Content That Google’s Algorithm Will Love Instantly
Check category texts (buying guides), product descriptions, blog and wiki articles with the reverse engineered formula (WDF*IDF) that Google is using to make sure you haven't forgotten or over-thematized a subtopic within a topic cluster.
Get a TODO list and an AI prompt that will make sure that after you have implemented the suggestions, your content is helpful to your users and is seen as such by Google's algorithm. It's easy to use and gives a huge competitive advantage, especially for Google's AI Mode.

Hands-On Workshops
Be One Step Ahead With the Newest AI SEO Tactics
Join live workshops or watch workshop recordings on important topics like SEO relaunches, AI SEO for Google's AI Mode, AI Overviews, LLMs like ChatGPT or free Q&A sessions.
Learn the newest SEO tactics from a proven SEO expert that actually move the needle.
1on1 SEO Consultations
Get SEO Support From An Expert When You Need It The Most
Some SEO issues can't wait and sometimes you just need the confirmation of an SEO expert that your plan or solution is correct.
Submit a question and receive a tailored, private hands-on guidance from a proven SEO expert with 23 years of experience.

SEO Checklists & Templates
Deliver Reliable SEO Results Much Faster and With More Confidence
Stop making the same mistakes as others, skip the trial and error with ready-to-use resources. Access proven SEO audit checklists, developer ticket, and reporting templates to streamline your SEO workflow and deliver reliable results faster.
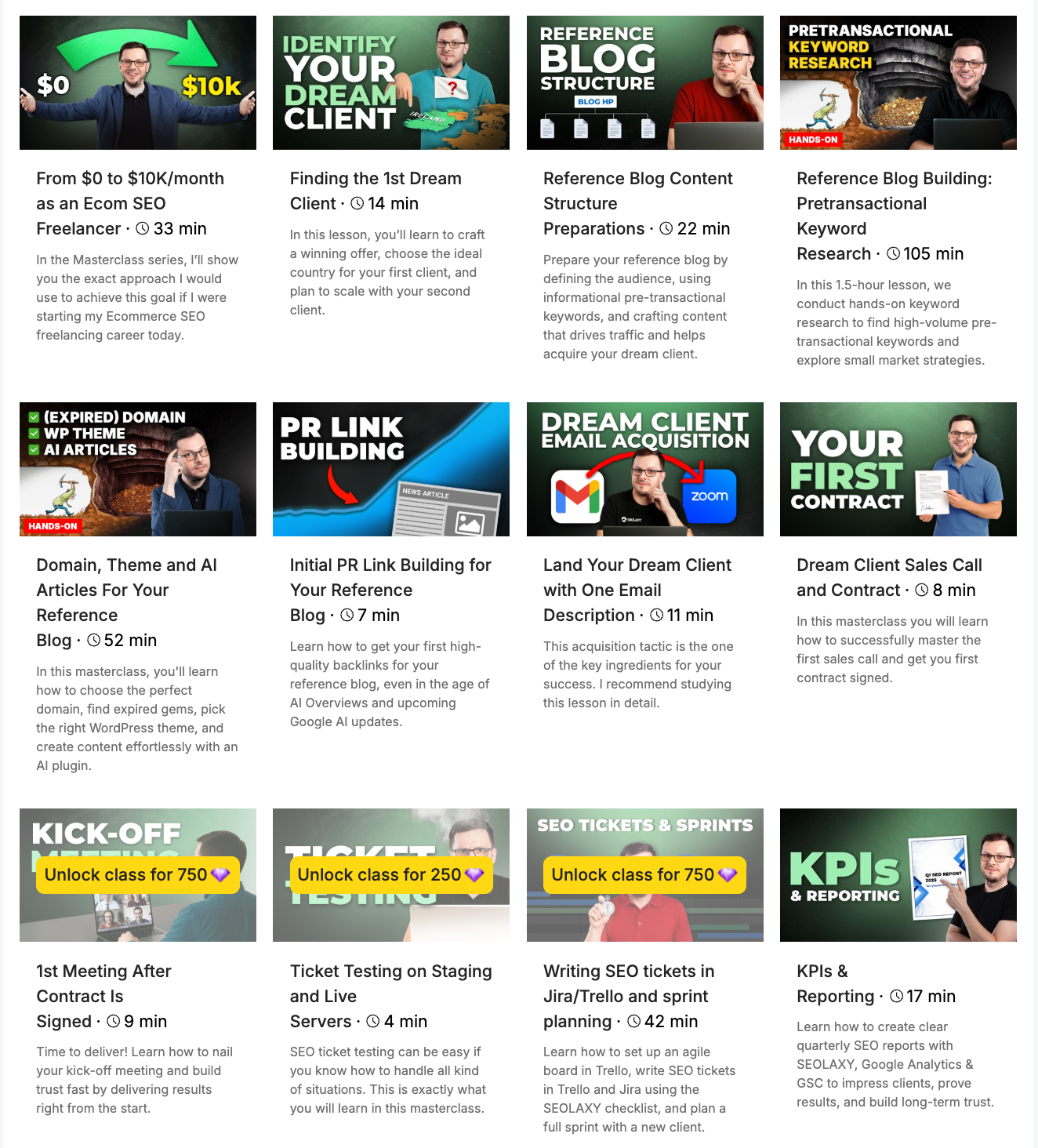
SEO Freelancing Masterclass
Start SEO Freelancing The Smart Way Without Quitting Your Job
Learn how to build an Ecommerce SEO freelancing career the safe way as a side job by landing well-paying clients and delivering fast and reliable results that protect your reputation.
You'll learn how to pick the right niche, how to target clients which can afford paying you $5000 monthly, how to do outreach that gets replies and to handle sales calls, how to get your first big contract signed with confidence and how to increase KPIs fast and reliable.

SEOLAXY Certification & Professional Profile
Stand Out As A Certified Ecommerce SEO & AI Specialist
Join SEOLAXY and take one of three levels of certification exams. If you pass, you'll earn a recognized Ecom SEO & AI certificate that proves your skills and elevates your career.
As a certified specialist, you'll be listed on our "SEOs for Hire" landing page, which potential clients visit in search of Ecom SEO & AI specialists. This way, clients will come to you.
All SEOLAXY members gain access to a profile where they can showcase their skills, client references, visibility graphs demonstrating real results, and additional knowledge badges.
Proven Ecom SEO Tactics For Explosive Organic Traffic & Sales Growth👇


Meet Nedim
Over the past 23 years, I've helped SEOs to start their freelancing career and acquire thousands of dream clients and generate millions of dollars.
I do this by showing them how to find dream clients and keep them by producing amazing Ecommerce SEO results using systematic approaches.
The result is they create massive organic sales growth for their clients which in turn blows up their confidence, credibility and income.
The emails I receive showing me how I've changed peoples's lives in just a few weeks, and watching SEOs go from $0 and struggling, to making tens of thousands fast, are incredibly rewarding.

SEOLAXY Pricing
The SEOLAXY membership costs $97 per month.
After you start your membership, you will receive 970 gems (digital tokens) each month.
ALWAYS UNLOCKED
While your membership is active, you have access to:
- SEOLAXY Community
- SEOLAXY Profile
- Live Q&A Workshops and Their Recordings
UNLOCK WITH GEMS
You can spend your gems on:
- WDF*IDF Tool Analysis
- SEO Freelancing Masterclass Lessons
- AI SEO Live Workshops and Their Recordings
- 1on1 SEO Consultations
- SEO Checklists & Templates
- Certification Exams
As a welcome gift, you will receive our Ecommerce SEO Audit Checklist.
You will also receive 3 bonus gems every time you log in (once every 24 hours).
Your membership can be paused or canceled at any time.
Frequently Asked Questions (FAQ)
FAQs Before Becoming a SEOLAXY Member
Here you can find the most frequent questions from users before they join SEOLAXY.
Do you issue a valid invoice?
Yes, we issue invoices with a German VAT number for both individuals and companies.
Can my company pay for my membership?
Yes, your company can pay the membership fee for you. This option will appear during the registration process under the payment method. Group purchasing for multiple employees under the same account is currently not available.
Can I share my account with someone else?
No, it is not possible to share the account with multiple people. Those who attempt to do so will have their account deactivated without any prior warning.
Which payment methods are available?
The available payment methods are Credit/Debit Card and PayPal. If you choose the annual payment option, you can also pay via wire transfer.
I want to register, but I can't enter the required information in the personal data and payment fields.
Here are a few things you can try: 1. Refresh the page and try again. 2. Clear your browser cache and cookies, then try again. 3. Ensure you're using a supported browser and that it's up to date. If you still experience difficulties after these steps, please contact us.
Which company is behind the SEOLAXY?
The SEOLAXY is a project of the German company BIGBURG GmbH.